最近在做的一个科研训练项目需要向某一交叉领域的专家们发送问卷调查。于是想到通过爬虫爬取国内各大高校在环境、建筑、能源等专业的教授的信息(姓名、邮箱、研究领域等等),再根据研究方向初步筛选,得到待定的专家组名单。🕷️
预先准备#
安装python第三方库:requests,re,csv(必要)
正则表达式在线测试工具:在线正则表达式测试 (oschina.net)(非必要)
分析源码#
教师名录#
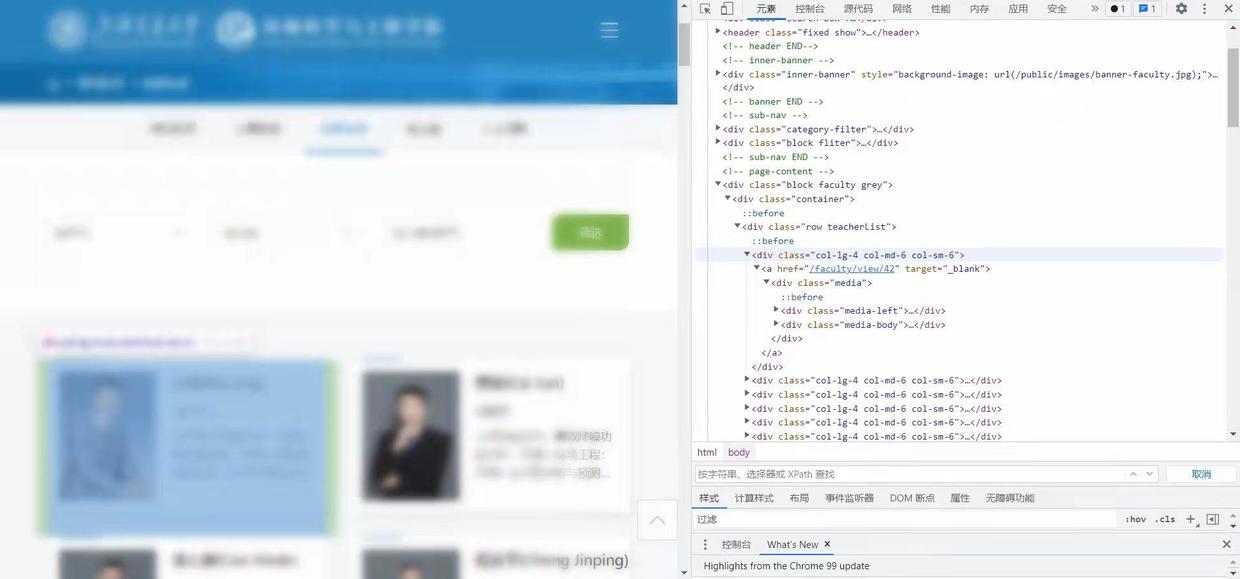
以上交的环境科学与工程系为例,先找到教师名录的网页。然后F12查看源码,找到转向教师个人主页的链接。可以看到个人主页的链接在源码里统一格式为<a href="/faculty/view/XX" target="_blank">,其中XX是编号或者姓名缩写。点进链接后发现网址的格式为https://sese.sjtu.edu.cn/faculty/view/XX,可见/faculty之前的内容被省略了。与之相对应,用来匹配个人主页链接的正则表达式为
1
|
<a href="/faculty/view[^"]*
|
得到匹配的结果后需要拼接成正确的链接。
1
2
3
4
5
|
...
match_person = re.compile(r'<a href="/faculty/view[^"]*') #匹配列表的老师们的个人主页网址
person_list = match_person.findall(root.text)
...
url = 'https://sese.sjtu.edu.cn/' + person_list[i].split('="')[1] #拼接得到完整的个人主页网址
|
查看教师名录网页
个人主页#
在个人主页上继续分析源码,姓名、邮箱、研究方向在源码里的统一格式分别为<h5 class="media-name">老师的姓名XXX</h5>,电子邮件:XXXX@XXXX.edu.cn,<h2>研究方向</h2><p>对主要研究方向的简单概括XXXX</p> 。其中研究方向这一栏被注释掉了,替以更详细的介绍。但是我们只需要这个简单版本就可以了,所以采用注释部分的内容。用于正则表达式匹配和字符串清理的代码:
1
2
3
4
5
6
7
|
match_name = re.compile(r'<h5 class="media-name">[\u4E00-\u9FFF\.]*') #匹配姓名
match_email = re.compile(r'电子邮件[:: ]*[\w\.]*@[\w\.]*') #匹配电子邮箱
match_research = re.compile(r'研究方向</h2>[^<]*<p>[^<\u200b\u200d]*') #匹配研究领域
name = match_name.findall(person.text)[0].split('>')[1]
email = match_email.findall(person.text)[0].split(':')[1]
research = match_research.findall(person.text)[0].split('<p>')[1]
|

整个爬虫的代码#
由于高校的教师主页一般不会采用反爬虫技术,因此不需要采取Header设置之类额外的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import requests
import re
import csv
f = open('教师列表.csv', 'w') #创建文件
writer = csv.writer(f)
writer.writerow(["index","name","email","researches","website"]) #列表的标题行
root_url = 'https://sese.sjtu.edu.cn/faculty/all' #教职工列表的网址
root = requests.get(root_url, timeout=30)
root.raise_for_status()
root.encoding = root.apparent_encoding
match_person = re.compile(r'<a href="/faculty/view[^"]*') #匹配列表的老师们的个人主页网址
person_list = match_person.findall(root.text)
for i in range(len(person_list)): #遍历所有教师
url = 'https://sese.sjtu.edu.cn/' + person_list[i].split('="')[1] #拼接得到完整的个人主页网址
person = requests.get(url, timeout=30)
person.raise_for_status()
person.encoding = person.apparent_encoding
match_name = re.compile(r'<h5 class="media-name">[\u4E00-\u9FFF\.]*') #匹配姓名
match_email = re.compile(r'电子邮件[:: ]*[\w\.]*@[\w\.]*') #匹配电子邮箱
match_research = re.compile(r'研究方向</h2>[^<]*<p>[^<\u200b\u200d]*') #匹配研究领域
try:
name = match_name.findall(person.text)[0].split('>')[1]
except:
name = '?'
try:
email = match_email.findall(person.text)[0].split(':')[1]
except:
email = '?'
try:
research = match_research.findall(person.text)[0].split('<p>')[1]
except:
research = '?'
row = [i+1, name, email, research, url]
writer.writerow(row) #写入文件
print(row)
f.close()
|
爬取效果#

这一方法的问题在于,写爬虫的工作量和爬取成功率非常取决于院校网页源码的标准程度。一些个人网站做得不太好的院校,不同老师的个人主页格式非常不统一,字体、排版、内容顺序等等各有千秋,使得我们很难从网页源码上识别出想要的信息。有时候适用于教师A主页的正则表达式,在教师B的主页上可能什么都匹配不到。这也是为什么我在写个人主页的findall命令时用了try语句——如果爬取失败了就用“?”替代,避免报错中断。
在尝试了不同学校的网站之后,发现“研究领域”的信息是格式最不统一的,因此也是爬取失败率最高的。如果个人主页没有专门给邮箱地址设栏,那么邮箱地址也很可能爬取失败。写一个适用情况较广的正则表达式是很重要的,可以多查看几位教师的主页源码,找一找共同的规律。作为第一次听说正则表达式这一概念的新手,我都是先将源码复制到在线测试工具里,确认自己写的正则表达式能够成功之后再放进代码当中。
教师姓名和个人主页网址一般情况下不会爬取失败,因为在职教师列表的页面通常有规律可循。因此非常建议记录每位老师的个人主页网址,便于有需要的情况下手动访问查阅。
同样发表于简书:爬虫记录:尝试用Python爬取教授邮箱 - 简书 (jianshu.com)