本篇是MMDetection学习应用过程中的踩坑记录,随学习情况更新。
训练报错:CocoDataset缺少update_skip_type_keys属性
运行条件:
pycocotoolsversion: 2.0.7mmengineversion: 0.8.4
使用dataset_type = 'CocoDataset'训练模型,在倒数第15个epoch的时候会报错表示CocoDataset缺少update_skip_type_keys属性。
一开始以为问题出在pycocotool包上,于是安装卸载了好几轮,还尝试了用mmpycocotools替换pycocotools,但是都不能解决问题。经过调试发现报错发生在mmengine包里,即site-packages/mmdet/engine/hooks/yolox_mode_switch_hook.py的第50行:
|
|
神奇的是将这一行直接注释掉之后依然能够正确地将模型训练出来,基本不影响正常的使用。于是就不再去动它了……😅

GPU加速模型训练
核对GPU信息
有独立显卡(GPU)的电脑上可以用GPU来提高模型训练的速度。在使用GPU训练之前需要先安装CUDA。可以用如下代码来查看本机的GPU信息1:
在本机上打印出来的结果依次为:
启用GPU训练
MMDetection的官方文档里说可以通过CUDA_VISIBLE_DEVICES=$GPU_ID来指定选优单一的GPU进行模型训练2,例如
|
|
但是上述命令在Windows平台中无法运行,命令行里会提示'CUDA_VISIBLE_DEVICES' 不是内部或外部命令,也不是可运行的程序
或批处理文件。在Windows中的workaround有很多种方式,其中我个人比较建议在训练脚本tools/train.py里插入:
相比于其他方案(例如添加系统环境变量、在cmd窗口里临时设置变量等等),直接写进训练代码里具有更好的可迁移性,换到另一台电脑上时不需要重新再麻烦地设置一遍(前提是另一台电脑也有独显和CUDA)。
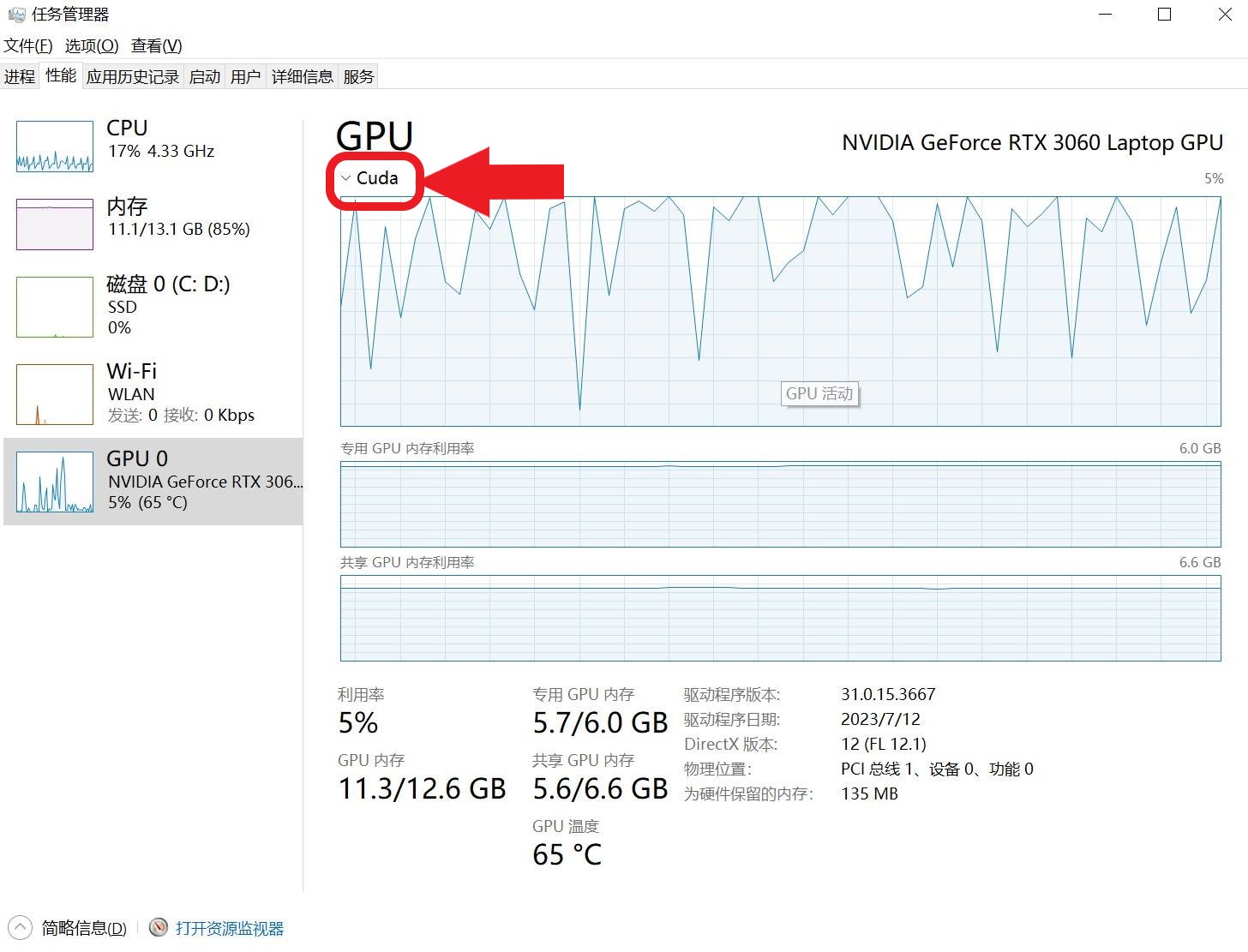
查看GPU占用率
打开任务管理器,把GPU的引擎设置为Cuda,就可以查看模型训练时GPU的占用率。如果发现GPU的占用率很低,但是CPU的占用率接近100%,可能是因为数据传输量过大。可以尝试减小num_workers、img_scale等参数来解决CPU相对于GPU的瓶颈问题。
不同的损失函数含义
训练模型时,每一个epoch会打印出格式如下的信息:
|
|
其中涉及到几个不同损失函数,根据网上的资料粗略地区分一下每个函数的特点——
loss:损失函数用于衡量预测值与真实值之间的差异。
loss_cls:目标检测算法的分类损失,衡量预测边界框的分类正确性。
loss_bbox:衡量预测边界框与地面真实对象的“紧密程度”的损失。
loss_obj:目标对象的损失函数。